OpenAI GPT-5.5 lidera ranking de IA, mas ainda gera dúvidas
Por Brian Wang · 2026-04-23
GPT-5.5 da OpenAI lidera o ranking de IA, mas ainda gera dúvidas. Veja benchmarks, custo por token e o que isso muda no mercado.
OpenAI voltou ao centro das atenções no mercado de inteligência artificial com o GPT-5.5, modelo que, segundo avaliações citadas pela publicação original, alcançou a liderança do Artificial Analysis Intelligence Index por uma margem de três pontos. O resultado encerra um empate triplo com Anthropic e Google e recoloca a empresa na posição de destaque em um cenário cada vez mais competitivo entre os principais laboratórios de IA. Ainda assim, os primeiros sinais sobre o desempenho do modelo sugerem uma leitura mais cautelosa: embora haja indicações de maior velocidade e bons resultados em alguns testes, outros aparecem apenas medianos, o que faz com que a avaliação geral permaneça em aberto.
Esse contraste entre liderança em benchmarks e percepção de salto limitado resume bem o momento atual da corrida de modelos de linguagem. A notícia mostra que o GPT-5.5 não foi apresentado como uma ruptura tecnológica, mas como uma evolução relevante em um ecossistema em que melhorias incrementais já podem alterar a disputa entre empresas. Em inteligência artificial, pequenas vantagens em precisão, custo e eficiência operacional podem ser tão importantes quanto a capacidade bruta do modelo, especialmente quando o uso ocorre em escala corporativa.
O que os resultados apontam
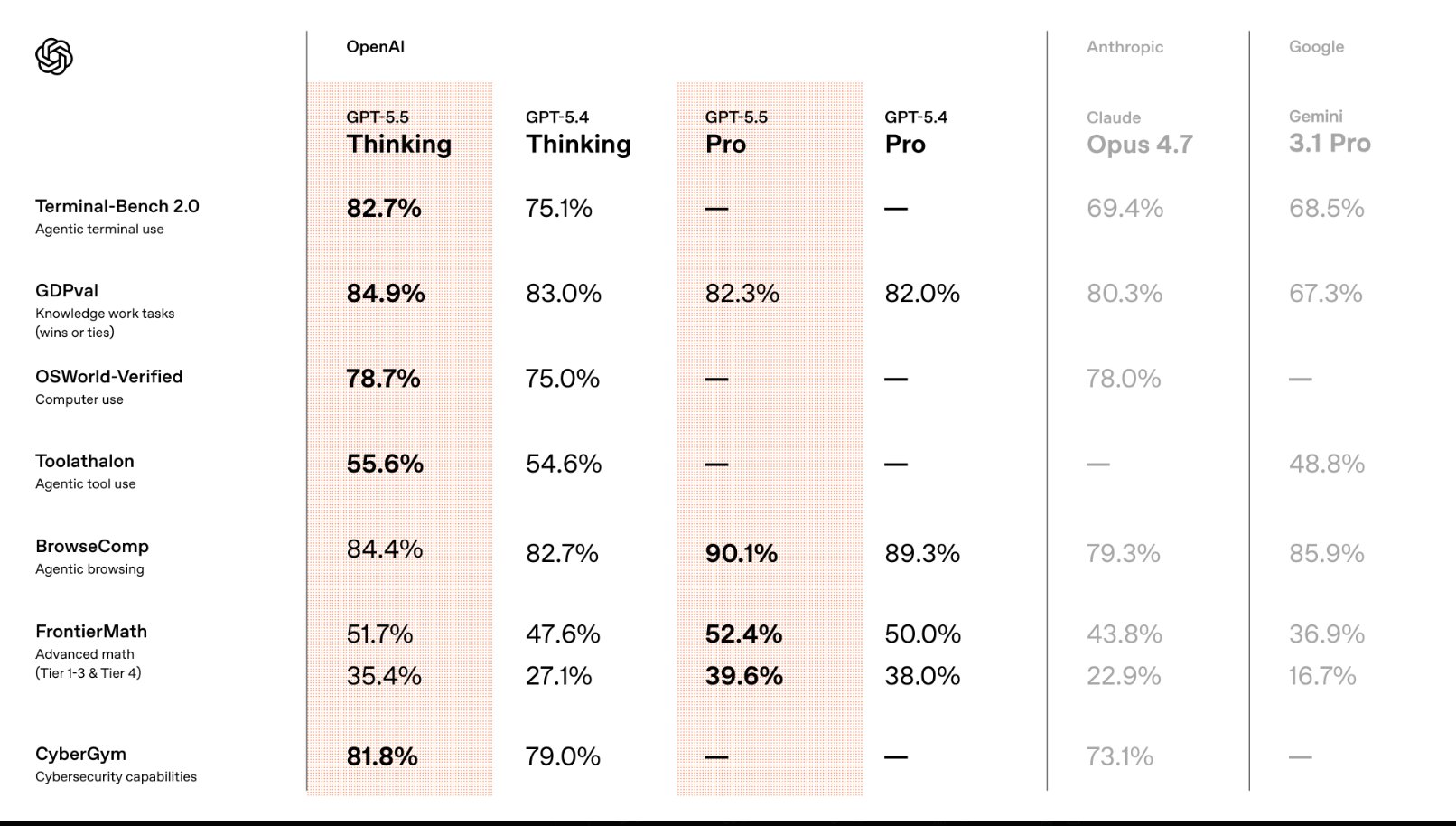
De acordo com o texto original, o GPT-5.5 da OpenAI liderou cinco avaliações de destaque. Entre elas estão o Terminal-Bench Hard, o GDPval-AA e o recém-hospedado APEX-Agents-AA. O modelo também apresentou a segunda colocação em outros testes, ficando atrás apenas de modelos da própria OpenAI em CritPt e AA-LCR, além de ter ficado em segundo lugar diante do Gemini 3.1 Pro Preview em três avaliações adicionais. Esses dados indicam um desempenho amplo, mas não uniformemente dominante em todas as frentes analisadas.
Os maiores ganhos do GPT-5.5 apareceram em dois pontos específicos. O primeiro foi o AA-Omniscience, benchmark descrito como uma avaliação de conhecimento e alucinação, em que o modelo obteve aumento de 14 pontos. O segundo foi o τ²-Bench Telecom, um teste voltado a agentes de atendimento ao cliente, no qual o avanço foi de 7 pontos. Essas melhorias sugerem ganhos importantes em áreas sensíveis para aplicações reais, como confiabilidade informacional e execução de tarefas em contextos de suporte ao usuário.
Ao mesmo tempo, a própria cobertura destaca que algumas respostas do modelo ainda são consideradas medianas. Isso reforça a ideia de que a liderança em rankings não significa necessariamente uma superioridade absoluta em todos os cenários de uso. Em inteligência artificial generativa, o comportamento pode variar conforme a tarefa, o tipo de prompt, a necessidade de raciocínio e o volume de contexto processado. Assim, o ranking oferece um retrato importante, mas não encerra a discussão sobre o valor prático de um modelo.
Benchmarks e o que eles medem
Os benchmarks citados na notícia são avaliações padronizadas usadas para comparar sistemas de IA em tarefas específicas. O Terminal-Bench Hard, por exemplo, sugere um teste mais exigente relacionado ao uso de terminal e execução de ações técnicas. Já o GDPval-AA e o APEX-Agents-AA aparentam medir capacidades de agentes em contextos mais complexos, embora a notícia não detalhe exatamente a metodologia de cada um. O ponto central é que esses testes ajudam a avaliar não apenas a geração de texto, mas também a aptidão do modelo para resolver problemas e seguir instruções em fluxos de trabalho mais próximos do uso corporativo.
Outro termo importante é alucinação, que no contexto de IA se refere à geração de respostas incorretas ou inventadas com aparência convincente. O benchmark AA-Omniscience, descrito como uma avaliação de conhecimento e alucinação, é relevante porque mede um dos principais desafios da inteligência artificial generativa: a capacidade de responder de forma precisa e confiável. Reduzir esse tipo de erro é uma prioridade para aplicações em empresas, atendimento ao cliente, busca interna e ferramentas de apoio à tomada de decisão.
A notícia também menciona o conceito de reasoning effort levels, ou níveis de esforço de raciocínio. Embora o texto não aprofunde a definição, a ideia sugere diferentes modos de processamento do modelo, com maior ou menor capacidade de dedicar recursos computacionais a uma resposta. Em modelos avançados, isso costuma se relacionar ao equilíbrio entre qualidade, latência e custo. Quanto mais esforço de raciocínio, maior a chance de respostas elaboradas, mas também pode haver aumento no tempo de processamento e no consumo de tokens.
Velocidade, custo e eficiência operacional
Um dos pontos mais relevantes da notícia é a relação entre desempenho e custo. O texto informa que o preço por token dobrou em comparação ao GPT-5.4, passando para US$ 5 por milhão de tokens de entrada e US$ 30 por milhão de tokens de saída. Em um primeiro momento, esse aumento poderia representar uma piora na viabilidade econômica do uso do modelo. No entanto, a reportagem afirma que houve uma redução de cerca de 40% no uso de tokens, o que absorve boa parte da alta e resulta em um aumento líquido de aproximadamente 20% no custo para executar o Intelligence Index.
Essa informação é importante porque, em modelos de IA, o custo total não depende apenas do preço cobrado por token. Também entram na conta a quantidade de tokens consumidos por consulta, a eficiência do fluxo de uso e o número de interações necessárias para chegar à resposta desejada. Um modelo que produz resultados melhores com menos tokens pode ser mais vantajoso do que outro teoricamente mais barato por unidade. Por isso, a redução de consumo mencionada na notícia tem impacto direto na análise de eficiência operacional.
Para empresas que integram IA em produtos, atendimento, automação de processos ou análise de dados, essa diferença é central. Uma melhora em qualidade acompanhada de uso menor de tokens pode viabilizar novas aplicações ou reduzir despesas em escala. Por outro lado, um aumento líquido de custo exige revisão de orçamentos, arquitetura de produto e critérios de adoção. A notícia sugere que o GPT-5.5 pode ser competitivo, mas ainda demanda avaliação cuidadosa antes de adoções mais amplas.
O significado da liderança para o mercado de IA
Ao voltar à liderança do Artificial Analysis Intelligence Index, a OpenAI reforça sua posição em uma disputa que inclui Anthropic, Google e novos concorrentes. Em um setor marcado por avanços rápidos, o topo dos rankings funciona como uma referência pública importante, influenciando percepção de mercado, interesse de desenvolvedores e decisões de empresas que escolhem quais modelos integrar. Mesmo assim, a própria matéria destaca que o ganho não parece ser revolucionário, mas sim um avanço consistente dentro de uma sequência contínua de melhorias.
Esse tipo de movimento mostra como a competição em IA já não se resume à disputa por maiores capacidades gerais. Hoje, fatores como custo por token, velocidade de resposta, confiabilidade, redução de alucinações e desempenho em casos de uso específicos têm peso crescente. Em outras palavras, um modelo pode liderar um benchmark e ainda assim não ser a melhor opção para todos os cenários comerciais. A adoção passa por uma combinação de critérios técnicos, financeiros e operacionais.
Outro aspecto relevante é o fato de a notícia mencionar a existência de novos modelos chineses de código aberto. Embora o texto não detalhe esses lançamentos, a observação indica que a concorrência global continua se ampliando. Modelos abertos e desenvolvimentos fora do eixo tradicional das big techs aumentam a pressão por eficiência, acessibilidade e velocidade de inovação. Isso tende a acelerar o ciclo de atualização dos modelos fechados e a elevar o padrão mínimo esperado pelo mercado.
Impactos práticos para empresas e usuários
Na prática, a evolução do GPT-5.5 pode afetar diferentes tipos de uso. Para desenvolvedores, o modelo pode representar uma opção mais forte em tarefas que exigem raciocínio, execução de comandos ou atendimento automatizado. Para empresas, a melhora em benchmarks ligados a conhecimento, alucinação e suporte ao cliente indica potencial de uso em chatbots, assistentes internos, automação de triagem e ferramentas de produtividade. Já para usuários finais, o efeito esperado é uma experiência potencialmente mais rápida e precisa, ainda que nem todas as interações mostrem salto perceptível.
Ao mesmo tempo, a notícia evidencia que a adoção de modelos de ponta continua exigindo testes próprios. Benchmarks são úteis, mas não substituem a validação em produção. Uma empresa pode encontrar excelente desempenho em avaliações públicas e, ainda assim, ter limitações específicas em seus fluxos de trabalho, em sua base documental ou no idioma predominante do atendimento. Por isso, a decisão de migrar para uma nova versão costuma depender de métricas internas de qualidade, custo e satisfação do usuário.
No campo estratégico, a liderança da OpenAI pode influenciar a percepção de investidores, parceiros e clientes corporativos, especialmente em um momento em que a disputa por modelos de IA se tornou também uma disputa por ecossistemas. Plataformas, APIs, integrações e ferramentas de desenvolvimento ganham relevância tanto quanto o próprio modelo. Assim, cada avanço em ranking pode fortalecer a posição comercial da empresa, mesmo quando a diferença técnica absoluta não pareça transformadora.
Um avanço relevante, mas ainda em avaliação
O conjunto das informações aponta para um GPT-5.5 sólido, competitivo e com melhorias concretas em áreas importantes, mas não necessariamente disruptivo. A OpenAI recupera a liderança em um índice relevante, porém enfrenta um mercado em que rivais seguem próximos e em que o custo de operação continua sendo parte essencial da equação. A notícia também mostra que desempenho superior em alguns benchmarks não elimina a necessidade de análises mais amplas sobre confiabilidade, eficiência e aplicabilidade.
No cenário atual da inteligência artificial, esse tipo de lançamento reforça uma tendência clara: a disputa já não é apenas por quem produz o maior modelo, mas por quem entrega a melhor combinação entre qualidade, velocidade, custo e confiabilidade. O GPT-5.5 parece se encaixar nessa lógica como uma evolução importante, embora ainda dependa de mais tempo e uso real para que seus efeitos sejam plenamente mensurados.
Referência: https://www.nextbigfuture.com/2026/04/openai-gpt-5-5-has-good-ranking-scores-but-is-it-better.html
Sobre o autor
Brian Wang — Conteúdo revisado pela equipe editorial do GeraDocumentos, com foco em IA, produtividade e criação de documentos profissionais.